|

- Title
- Abstract
- Introduction
- The Challenge
- The Solution
- The Reckoning
- Juncture and Hard Experience
- Conclusion
- Bibliography
- Footnotes
Title:
"Providing Extra Service: What To Do With Migrated User Files?"
When faced with decommissioning our popular C90 machine, there was a problem of what to do with the 80,000 migrated files in 40,000 directories and the users' non-migrated files. Special software and scripts were written to store the file inode data, parse the DMF database, and interact with the tape storage system. Design issues, problems to overcome, boundaries to cross, and the hard reality of experience will be discussed.
Introduction
After five years of nearly constant use NERSC finally faced the prospect of decommissioning its popular Cray Y-MP C90, which had 16 PEs, 1 gigaword of memory, and ran UNICOS 9.2. This resulted in significant problems and hurdles to overcome. Primarily, the C90 was host to approximately 1450 users, where each user was allowed to have Super Homes of up to 3 Gigabytes of file storage (an aggregate total of on-line and off-line files), in addition to their archival storage accounts. Management made the decision to keep the machine available until the very last day (December 31, 1999) to satisfy our commitment to our user base to provide the maximum number CPU cycles. There would be an allowance of one week for system clean up before returning the machine to the vendor.Having such a large space allocation, naturally the users tended not to clean and trim their file storage. They had accumulated approximately 60 Gigabytes of on-line storage in their home directories, and 60 Terabytes of off-line storage via the Data Migration Facility (DMF). There were other on-line disks that provided up to 100 Gigabytes of temporary storage, but these directories were not backed-up and there was no guarantee that the files couldn't be removed at any moment. However, there was an understanding that only those files not accessed within a certain number of days would be candidates for removal and only if there was a need for space.
Since there was only a one week period for handling the clean-up of user files, it was out of the question to even contemplate unmigrating the user files and spooling them to tape. There were a number of reasons. The tape storage system was connected to the C90 via a hippi connection with a maximum transfer rate of .8 Gigabits/sec. The retrieval of all the off-line files would take approximately 7 days to accomplish. Even if this were feasible, there wouldn't be enough on-line disk space to handle but a few users at a time. The other option would be for users to back-up their own files, but this would result in similar problems as users contend with each other while unmigrating their files in order to transfer them over to the archival storage system. The likely result would have been that larger files would have been re-migrated back to off-line storage as more recent requests filled up the disk storage system, resulting in migrated file thrashing.
The least desirable option was to do nothing and tell the users that their files would just vanish into eternal oblivion once the machine was closed down. This had been done with prior NERSC decommissioned machines. The allowed continuing storage on these machines was limited to well under 100 MB per user, and also there were no migrated file facilities. In those cases, it would have been relatively easy for the user to archive all his files to the archival storage system. (Back-ups were performed anyways and kept for 6 months for emergency retrieval.)
An alternative presented itself due to the nature of DMF
[1].
When files are migrated DMF assigns them an id and key,
transfers the file to the archival storage system, and then removes
the file from on-line storage. Therefore, migrated files
are already on the tape storage system, which is the same archival
storage system that the users send their files to.
This presented the most likely solution: just "rename" the migrated
files within the the archival storage system to something identifiable
by the owners.
The Challenge
The dilemma needed to be resolved within 2 months. It required interfacing
between two different groups, one in charge of the C90 system, the other over
the tape storage system.
Once the necessary information regarding the migrated files was collected,
the data and the task had to be portable to at least one other machine.
This was in order
to anticipate any problems that may delay the renaming task until after
the C90 was packed up. Fortunately, NERSC has a J90 cluster, which
has an architecture very similar to the C90. This eliminated much
of the portability gyrations in connection to the file inode
structure.
The challenge was to gain a complete and sufficient enough
knowledge of the systems and structures involved such that
the task could be performed once the C90 was removed.
There were many aspects to consider.
First, what and how to store the migrated file path and name in addition
to the file inode.
Second, how to interface to the DMF database, and how to transfer
this data to another platform.
Third, how to interact with the tape storage system.
Migrated File Inode Information
Crays running UNICOS have a file system similar to any
UNIX system. The location of any file, from the user perspective,
is somewhere in a hierarchal directory tree structure.
From the system perspective, each file has an inode block
that contains the information necessary to point to the disk
blocks that comprise the file and other information useful
to the operation system
[2],
such as: the last access time (atime),
last inode modification time (ctime), the last time the
file was changed (mtime), size of file (size),
owner (uid), group (gid), the type of file and permissions
(mode).
One piece of information lacking from the inode is the
file name or path. That information only exists in the sequence of
directory files that constitute the path.
In addition to the fields in the inode mentioned above,
UNICOS has a number of other fields. The ones of interest to
this project were the data migration mode (dm_mode),
and the data migration id and key (dm_id and dm_key).
The dm_mode indicates whether the file is on-line (disk resident)
or off-line (tape storage) or both. The id and key identify
or point to the migrated file entry in the DMF database.
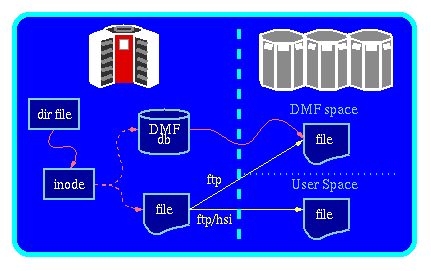
Figure 1: A UNIX file system with DMF.
DMF Database
The DMF database (DMFdb) tracks the off-line file. A DMF entry reproduces much of the inode information such as: size, inode number, uid, and, most importantly, a key and id generated path and filename of the migrated file in the tape storage system. One piece of information it does not have is the original file name or path as it exists on the on-line disk.
The unique key and id generated path and filename for each entry
may not give the exact path and filename used on the tape storage
system, because the DMF requires a "custom" piece that handles
the file naming and the details on how to transfer files to
the tape storage system.
The path and name stored in the DMFdb were typically of the
form:
/testsys/migration_dmf/ama_migrate/3381d338_8/000000408055,where the horribly long numerical path and file name were uniquely hashed from the dm_id and dm_key. For NERSC, however, the actual path and file name in the tape storage system for this example would be:
/DMF/ama_migrate/migration_dmf/3381d338_8/00000040805,which is just a trivial modification and rearrangement of the path.
The structure of the DMFdb was too chaotic or irregular
to allow non-vendor written code to access the database directly.
Neither does SGI/Cray provide a standard API library to allow a user
code to search the database directly to find an entry corresponding to a given
dm_id and dm_key.
Therefore, given the expediency of the task, it was better to dump
the DMFdb to an ASCII text file, via "/usr/lib/dm/dmdbase -t dmdb",
and then to parse this generated text file.
HPSS Tape Storage System
The tape storage system at NERSC uses HPSS, a high performance
mass storage system, which was
developed by a consortium of industrial, university,
and government sites, and is deployed at several super-computing facilities
nationwide.
HPSS is a storage management system that is designed to store large
quantities of data and to put and retrieve the data at extremely high
data rates. The storage of
large quantities of data is provided by HPSS through its control of
large tape libraries from such vendors as StorageTek and IBM.
The management of data in these libraries is simplified by
HPSS through the use of a hierarchical name-space, like the name-space
provided by a regular UNIX disk file system.
Users organize their data on tapes as if they were contained in a very
large file system. HPSS basically isolates the users from the reality
that their data is stored on individual tape cartridges.
Communication to the HPSS can be done via ftp and variants or the
HPSS interface utility hsi, which uses a different authentication
protocol and provides a familiar interface
(similiar to cfs a NERSC tool
dating back to the CTSS operating system). NERSC
uses DCE authentication to allow secure access from batch scripts.
One concern was that the task of renaming nearly 100,000 HPSS files
may overload the HPSS database machine. However, scaling smaller tests
indicated that the entire process of renaming this number of HPSS files
would take approximately 10 hours. This was not excessive considering
the scope of the entire project.
The Solution
Much of the time was spent analyzing the differing subsystems,
writing codes and scripts to test various possibilities,
negotiating with the different groups and acquiring the
necessary resources, and gaining practical experience.
The first piece to contend with is the inode information. This was accomplished with a custom piece of standard C code [3] that walks a depth-first descent through the user directory hierarchy wrapping the inode struct stat, into another struct along with the file name. A parallel directory tree, that mirrors the user directory tree, is simultaneously created and this data struct is appended to a file in the corresponding directory. The directory path is preserved in the mirror directory structure and the file name and inode information (struct stat) is preserved in a datafile in each of these mirrored directories. Since only migrated files were of interest for this task, many of the directories could be void of this datafile. These empty directories were subsequently trimmed and later experience showed that this would become more of a bottle-neck than expected. The remaining information is easily ported by copying the entire directory structure to another machine (via tar or cpio).
The second piece to resolve was interfacing with the DMFdb. As mentioned above, SGI/Cray does not provide an library interface to the DMFdb. This caused some concern, since the desired approach was to access the database directly. However, since real-time access was not necessary and the machine would be in a quiescent state during this task, creating a text dump of the DMFdb would be sufficient. The DMFdb dump to an ASCII text file was accomplished via "/usr/lib/dm/dmdbase -t dmdb". To make the task of accessing the DMFdb information faster, the ASCII text dump was pre-read by a home-grown utility which then placed the necessary information into a GNU database managed file (gdbm) 1 2. All subsequent random accesses are then confined to this gdbm file.
The third piece involved interacting with the HPSS. At the time, the DMF interaction with HPSS was performed one file at a time using ftp to perform the directory creation (if necessary) and to transfer the file. Since the task only required directory creation and file renaming, but for nearly 120,000 files 3, it was obvious that using the same model would add entirely too much overhead because a process would be created for each transaction and require authentication. Therefore, it would be better to start just one process and go through the authentication once, then perform all the transactions sequentially. One approach was to create a custom piece of software that would use hacked ftp sources. This was not desirable because it would be the most error prone and least flexible if crisis changes were required. Time was running out and a more flexible approach was needed. Another way was to fork/exec a child process to ftp or hsi and attach to its stdin and stdout/stderr. However, unless the child process program sets the user I/O to line buffering, the parent can send the transaction, but due to buffering it won't receive immediate feed-back and be able to correct any situations as they arise. To get immediate or unbuffered I/O, the code would have to use the pseudo-tty mechanism. This adds further complexity. Once this threshold is contemplated, better avenues become available such as using "expect".
expect is a scripting language, based on Tcl (tool command
language), and is designed precisely for this kind of interfacing with
interactive tools. It took relatively little time to first port
and install Tcl 8.0.4 to
the SGI/Crays4,
and then to build expect on top of that.
It was fairly straight forward to create
a script [4],
to interact with hsi and to handle exceptional cases
with some familiarity with Tcl.
But the code for reading the inode data
was required to have an interactive interface.
The Reckoning
The combination of custom code, custom database, and custom scripting
yielded a surprisingly robust method for accomplishing the task of moving
and renaming all the users migrated files to a recognizable hierarchal
directory structure.
Up to this point, all tests were done with small artificially
created directories with a mixture of migrated files and resident files.
I had access to the DMF account in the tape storage system; however,
this account had no privilege to change ownership of files (and generally
shouldn't need it).
On the C90, I was given the MLS sysadm security level,
which allowed access to the DMF tools and database, and to read
certain configuration files.
Last Minute Design Requirements
It was decided belatedly that the users' non-migrated files
would not be available from an alternative file system attached
to the remaining J90 cluster. Having the users request these
files from a back-up would create too much overhead for the
staff and for the users.
The obvious solution was to archive the non-migrated files for
each user in their home directory,
to force the migration of this archive,
and then to remove the non-migrated files.
The user's archive would be available along with the user's
migrated files.
This required a script to
- change to each user's home directory,
- find all the non-migrated files
- pipe the list into cpio (an archiver well suited for this),
- remove the same files if and only if all the prior steps completed successfully,
- create a README file with instructions for the users along with a list of files that were archived,
- finally, force migrate the archive and README file.
Politics
Neither the group in charge of the tape storage system or the C90 were willing to grant root or full access to an employee not within their own sphere of influence on a production system. Neither group had the flexibility or expertise to handle the task either. Therefore, many of the problems documented below weren't discovered until the task juncture, when the C90 was no longer a "production" machine and full access could be given. As for the HPSS file change ownership issue, a subsequent script was created from the database of users and home directories that could be run later on the tape storage system. (It turned out that nearly 60% of the listed users on the C90 did not have accounts for the HPSS.)Check-list
Before the task juncture, the efforts of all the parties involved were coordinated and a check-list of tasks was compiled to ensure smooth progress. The following check-list was followed once the C90 was restricted to users, final full back-up was performed, and the DMFdb was audited (cleaned).- Make sure have root access.
- Transfer home environment (dot-files, etc.) to somewhere in /tmp since the home directory structure will be decimated as the task progresses.
- Make sure auto-migration limits are disabled. (Don't want files to be migrated during the task.) Check /etc/config/dmf_config for MIG_THRESHOLD and FREE_THRESHOLD.
- Copy the necessary libraries, sources, and scripts to the new home directory. Compile and test.
- Run the script to individually archive, force migrate these archives, and remove all users' non-migrated files for each of the user file systems. Monitor the progress with "df -k -P".
- Reset the minimum size of migrated file by setting MIN_DM_SIZE to 4096 bytes in /etc/config/dmf_config. Restart the dmdaemon with /usr/dm/dmf.shutdown and /usr/dm/dmf.startup.
- Check that there are no more non-migrated files in the user space
with:
find /u ! -type m ! -type d -print - Run "/usr/lib/dm/dmhdelete -o 0d" to force the hard delete of soft-deleted entries in the DMFdb.
- Create the inode data-files and directories.
- Trim the empty directories for above (run a script to recursively "find" and list these directories and remove them).
- Create the GNU database from a DMF database dump.
- Archive the generated inode and DMFdb data and save elsewhere.
- Start running the expect script on the C90 to rename the migrated files in the tape storage system. Monitor as it progresses.
- Review logs for any problems, resolve as needed.
- Create list of user home directories and ownership. From this list create script of hsi commands to change ownership of the newly renamed files and directories from a privileged account.
- Notify C90 system staff to scrub disks and decommission machine.
- Celebrate!
Juncture and Hard Experience
Zero-hour finally arrived. As with any other one-time critical processes not everything could have been anticipated and there are always changes and fixes that need to be performed. The task was performed over the New Years holiday, near the end of the Lawrence Berkeley National Laboratory yearly shutdown (only a skeletal staff and only critical systems remain powered-up to conserve energy over the Christmas/New Year holiday).The C90 machine was turned over to this task at noon on December 31, 1998, which progressed continuously day and night for 3 days. The machine was turned over at 1:00pm on January 3, 1999, one hour after what was expected. Fortunately, many of the tasks could run unattended and a somewhat normal life could co-exist; however, it was still necessary to monitor the progress logs every 2-3 hours day or night near the end.
There were a few surprises. First of all, when archiving the user non-migrated files and directories, it was found that some users, either intentionally or not, had files and directories with non-printable characters or spaces. This had a tendency for the scripts to fail. They were modified to convert such characters to underscores (_) and rename the files and directories. This error happened early in the process and raised serious doubts whether the entire task could be completed on time. However, it did not adversely affect the schedule too much.
The bulk of the user directory archiving took approximately 6 hours.
Fixing the file naming problem took about another 4 hours.
An extended break was needed at this point to allow
DMF to complete the migration of all the user archives.
The DMF hard-delete of entries took 11/2 hours.
The creation of the inode data and directories
took 11/3 hours.
It was surprising that recursively trimming the empty directories
(starting with 41200 directories and finishing with 13600)
took in excess of 5 hours, since each find pass required approximately
30-50 minutes. The script was modified to perform only one find
execution per pass. This was unanticipated since all the tests were
performed on small directory trees, else the inode data and directories code would have been made "smarter"
to clean up such empty directories.
The dump and conversion of the DMFdb to a GNU database
took 1/2 hour.
The renaming of migrated files in the tape storage system took
the remaining 40 hours, with unscheduled
breaks due to "illegal" file names that crashed the
expect script.
There were 1250 files that couldn't be renamed in the tape storage system.
However, the time for decommissioning was approaching. These remaining
files were processed leisurely the next couple of days from the J90
cluster, and resulted from non-standard file names with unusual characters.
During the entire task, there were continuing fine-tuning and zero-hour
changes in the software and scripts for handling exceptional or
unanticipated conditions.
Conclusion
In conclusion, the immense task of handling the vast number of
user files (migrated or not) and directories for a popular machine
as it was decommissioned was performed successfully.
It required a wide skill-set, the ability to acquire or adopt
further skills as needed,
along with pragmatic reasoning to reduce the task to readily
accomplishable processes.
It also entailed working around the hurdles induced by
inter-organizational politics that could have
sidetrack the entire task.
The main beneficiaries were the users who could continue with their work
and access their old files. The users will have 6 months to access the old
C90 files before the files are permanently removed.
I anticipate that such exercises will be performed in the future
some 2-3 years when retirement is contemplated for
the current J90 cluster. However, I can think of better ways to
celebrate the New Years holiday.
Bibliography
- UNICOS Data Migration Facility (DMF) Administrator's Guide, SG-2135 2.5, Cray Research, Inc.
- UNICOS 10.0 stat(2) man page, or UNICOS System Calls Reference Manual, publication SR-2012, Cray Research, Inc.
- P.J. Plauger, Jim Brodie, "Standard C: Programmer's Quick Reference", Microsoft Press, 1989.
- Don Libes, "Exploring Expect", O'Reilly & Associates, Inc., 1995,
Footnotes:
1 The GNU database manager (gdbm) is similar to the standard UNIX dbm and even has a compatibility mode. The database uses a key and data model, where the key or data could be of any type of structure.2 GNU software is available via anonymous ftp at ftp://ftp.gnu.org/gnu or one of the mirror sites.
3 There was no definitive idea how many migrated files were being handled by DMF. The number of entries in the DMFdb was approximately 120,000, but a sizeable number were no longer valid and did not correspond to active user files. Once the database was audited and the user directories were processed, the resulting number of active user files was closer to 85,000.
4 SGI/Cray does provide Tcl/Tk via the cvt module; however, its version is 7.4 which is several years out of date and many of the Tcl add-ons require more recent versions.
5 A patch file with changes to the GNU find to handle SGI/Cray migrated files can be sent out by email.
Brought to you by: R.K. Owen,Ph.D.
This page is http://rkowen.owentrek.com/howto/dmfproj/article/index.html